به عنوان یک راهکار جذاب در عالم آمار و تحقیقات، نمونه برداری (نمونه گیری) آماری را برای کاوش در اعداد و اطلاعات جمعیتها تصور کنید. این مهارت محققان را قادر میسازد تا با کمک نمونههای کوچکتر از جمعیت، دادههای حیاتی را برای تحلیل به دست آورند. در مقالهی "نمونه برداری در علم داده چیست؟" به معرفی کامل این مقوله و فرآیندهای آن پرداختیم ولی مهمتر از همه روش های مختلفی از نمونهبرداری وجود دارد که باید آن را یادبگیریم. در این مقاله، با هم در دنیای جذاب نمونه برداری به سراغ این انواع و شیوههای آنها با مثالهای کاربردی میرویم.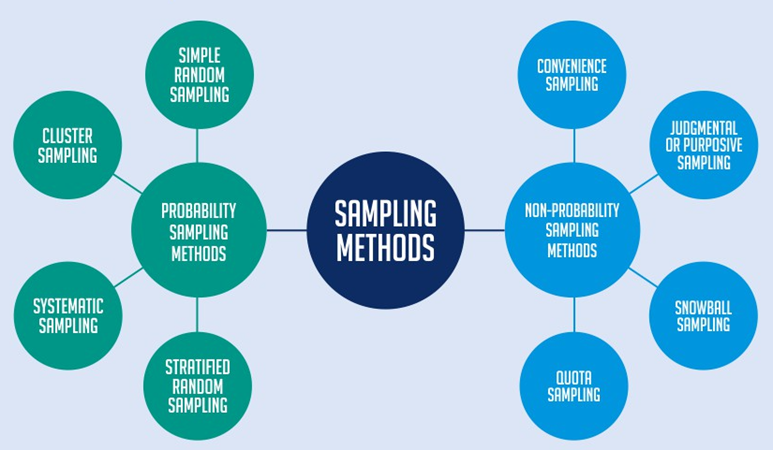
نمونه برداری در تحقیقات عملی دو نوع است: نمونه برداری احتمالی و نمونه برداری غیراحتمالی.
- نمونهبرداری احتمالی: که برخی از محققین از آن به عنوان نمونهبرداری تصادفی یاد میکنند، روش نمونهبرداری است که در آن محقق چند معیار را انتخاب کرده و اعضای یک جامعه را به صورت تصادفی بر اساس آن معیارها، انتخاب میکند. بنابراین، همه اعضا از فرصت برابر برای شرکت در نمونه بر اساس پارامتر انتخابی، برخوردارند.
- نمونهبرداری غیر احتمالی: در این روش، که به آن نمونهبرداری غیرتصادفی نیز گفته می شود، انتخاب نمونه براساس قوانین احتمالات صورت نمیگیرد و نمونه به کمک قضاوت انسانی حاصل میشود. بنابراین اشتباهات برآوردهای غیراحتمالی، اغلب غیر تصادفی و غیرقابل اندازهگیری است. در این روش، هر چقدر هم که حجم نمونه را بزرگ اختیار کنیم، نمونهها اغلب نمی توانند معرف واقعی جامعه باشند. اما با این حال گاهی اوقات نمونهبرداری غیراحتمالی، بهترین روش نمونهبرداری میباشد، مانند زمانی که امکان تهیه چارچوب نمونه وجود نداشته باشد.
چه عواملی در انتخاب روش نمونه برداری موثر است؟
تصمیمگیری برای انتخاب رویکرد احتمالی یا غیر احتمالی، به عوامل زیر بستگی دارد:
- هدف و محدوده مطالعه
- روشهای امکان پذیر جمعآوری دادهها
- مدت زمان مطالعه
- سطح دقت موردانتظار از نتایج
- طراحی چارچوب نمونه و قابلیت نگهداری آن
1. انواع نمونه برداری احتمالی با مثال
همانطور که گفته شد، در نمونهبرداری احتمالی هر یک از اعضای جامعه شانس یکسان برای انتخاب شدن دارند. این روش، عمدتا در تحقیقات کمی استفاده میشود و اگر میخواهید نتایجی تولید کنید که نماینده کل جامعه باشند، روشهای نمونهبرداری احتمالی بهترین انتخاب هستند. به عنوان مثال، در یک جمعیت 1000 عضوی، هر عضو 1000/۱ شانس انتخاب شدن به عنوان بخشی از یک نمونه را خواهد داشت. نمونه برداری احتمالی، سوگیری نمونه برداری را در جامعه حذف میکند و به همه اعضا اجازه میدهد در نمونه گنجانده شوند.
چهار نوع روش نمونهبرداری احتمالی وجود دارد:
1/1- نمونهبرداری تصادفی ساده (Simple random sampling)
یکی از بهترین تکنیکهای نمونهبرداری احتمالی که به صرفه جویی در زمان و منابع کمک میکند، روش نمونهبرداری تصادفی ساده است. این روش، یک روش قابل اعتماد برای به دست آوردن اطلاعات است که در آن تک تک اعضای یک جمعیت به طور صرفاً تصادفی انتخاب میشوند. هر فرد احتمال یکسانی برای انتخاب شدن به عنوان بخشی از یک نمونه را دارد و چارچوب نمونه باید شامل کل جامعه باشد. برای انجام این نوع نمونهبرداری، میتوانید از ابزارهایی مانند مولد اعداد تصادفی یا سایر تکنیکهایی که کاملاً بر اساس شانس هستند استفاده کنید. 
بیایید به دو نوع زیرمجموعه نمونهبرداری تصادفی ساده نگاه کنیم:
1.1.1- نمونهبرداری تصادفی ساده با جایگزینی
در اینجا، با حجم نمونه N، یک عنصر از جامعه را انتخاب کرده و آن را به جامعه برمیگردانید. این نشان میدهد که هر عنصر از جمعیت از نظر تئوری میتواند بیش از یک بار انتخاب شود. هر بار که فردی را انتخاب می کنیم، کل جمعیت انتخاب شده را برای انتخاب در دسترس داریم. به طور معمول، زمانی که جمعیت کم است، از این تکنیک استفاده میکنیم.
1.1.2- نمونه برداری تصادفی ساده بدون جایگزینی
در اینجا، هنگامی که فردی را از جمعیت انتخاب میکنید، آن را برنمیگردانید. با عبور از هر انتخاب، جمعیت موجود کاهش مییابد. این همچنین به این معنی است که برای اندازه نمونه N، فرآیند انتخاب را N بار تکرار می کنیم. معمولا وقتی حجم جمعیت زیاد است، به سراغ این روش میرویم.
مزایا:
- سوگیری کم به دلیل ماهیت تصادفی مجموعه نمونه
- با توجه به استفاده از مولدهای تصادفی، انتخاب نمونه ساده است.
- به دلیل نماینده جامعه بودن، یافته ها می توانند به طور گسترده تفسیر شوند.
معایب:
- در دسترس بودن بالقوه همه پاسخها ممکن است گران و زمان بر باشد.
- حجم نمونه بزرگ
برای مثال، در سازمانی متشکل از 500 کارمند، اگر تیم منابع انسانی تصمیم به انجام فعالیتهای تیمسازی داشته باشد، احتمالاً ترجیح میدهند که افراد را به صورت تصادفی انتخاب کنند. در این صورت، هر یک از 500 کارمند فرصت برابری برای انتخاب شدن دارند. یا اگر می خواهید یک نمونه تصادفی ساده ۱۰۰ تایی از 1000 کارمند یک شرکت بازاریابی رسانه های اجتماعی را انتخاب کنید، شما به هر کارمندی در پایگاه داده شرکت از 1 تا 1000 عدد اختصاص می دهید و از یک مولد اعداد تصادفی برای انتخاب 100 عدد استفاده میکنید.
عنوان تبلیغ: آموزش نمونه برداری در پایتون
1.2- نمونهبرداری سیستماتیک (Systematic sampling)
نمونهبرداری سیستماتیک مشابه نمونهبرداری تصادفی ساده است، اما معمولا انجام آن کمی آسانتر است. محققان از روش نمونهبرداری سیستماتیک برای انتخاب اعضای نمونه یک جامعه در فواصل زمانی معین استفاده میکنند. این امر مستلزم انتخاب نقطه شروع برای تعیین نمونه و اندازه نمونه است که می تواند در فواصل زمانی منظم تکرار شود. این نوع روش نمونهبرداری دارای یک محدوده از پیش تعریف شده است. از این رو، کمترین زمان را برای محاسبه نیاز دارد.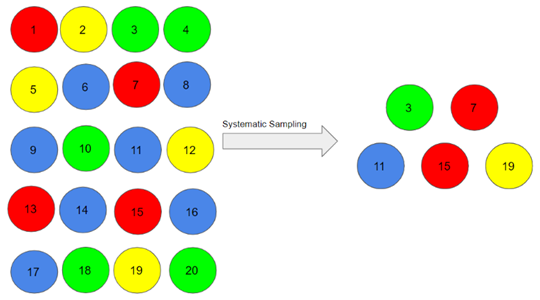
فرض کنید، ما با شخص شماره 3 شروع کردیم و حجم نمونه ی 5 را می خواهیم. بنابراین، فرد بعدی که انتخاب می کنیم در فاصله زمانی (۵/۲۰) = 4 از نفر سوم، یعنی 7= ۴+۳ خواهد بود.
3, 3+4=7, 7+4=11, 11+4=15, 15+4=19 مزایا:
- از نظر زمان و هزینه مقرون به صرفه است
- توزیع نمونه را در بین جامعه افزایش می دهد.
معایب:
- مهم است که جمعیت کامل را بشناسید.
- سوگیری نمونه احتمالی در صورتی که مجموعه داده شامل الگوهای دوره ای باشد.
مثال ۱: محققی قصد دارد یک نمونه سیستماتیک از 500 نفر در یک جمعیت 5000 نفری جمعآوری کند. او هر عنصر جامعه را از 1 تا 5000 شماره گذاری می کند و هر 10 نفر را به عنوان بخشی از نمونه انتخاب می کند ( حجم نمونه / کل جامعه = 500/50۰0 = 10).
مثال ۲: لیست کلیه کارکنان شرکت به ترتیب حروف الفبا مرتب شده است. از 10 شماره اول، شما به طور تصادفی یک نقطه شروع را انتخاب می کنید: شماره 6. از شماره 6 به بعد، هر 10 نفر در لیست انتخاب می شود (6، 16، 26، 36 و غیره) و در نهایت یک نمونه از 100 نفر خواهید داشت. اگر از این تکنیک استفاده می کنید، مهم است که مطمئن شوید هیچ الگوی پنهانی در لیست وجود ندارد که ممکن است نمونه را منحرف کند. به عنوان مثال، اگر پایگاه داده منابع انسانی، کارمندان را بر اساس تیم گروه بندی کند و اعضای تیم به ترتیب ارشد بودن فهرست شده باشند، این خطر وجود دارد که فاصله انتخابی شما از افراد، در نقش های پایین تر رد شود و در نتیجه نمونه به سمت کارمندان ارشد منحرف شود.
1.3- نمونهبرداری تصادفی طبقهای (Stratified random sampling)
نمونهبرداری تصادفی طبقهای روشی است که در آن محقق جامعه را به گروههای کوچکتری تقسیم میکند که همپوشانی ندارند و کل جامعه را نشان میدهند. در حین نمونهبرداری، می توان این گروهها را سازماندهی کرد و سپس از هر گروه به طور جداگانه& نمونهای استخراج کرد. در این روش، بر اساس نسبت کلی جمعیت، شما محاسبه میکنید که از هر زیرگروه چند نفر باید نمونهبرداری شود. سپس از نمونهبرداری تصادفی یا سیستماتیک برای انتخاب نمونه از هر زیرگروه استفاده می کنید. 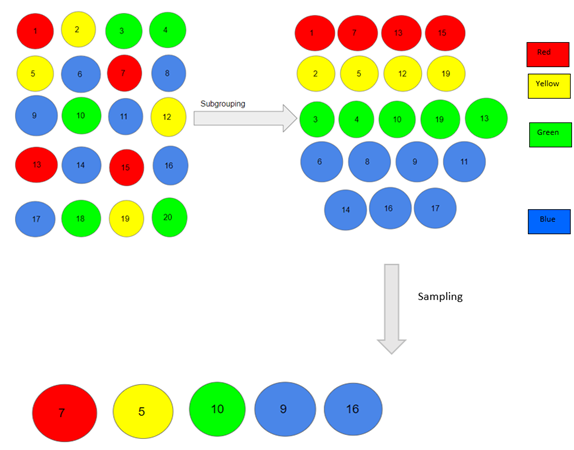
در اینجا، ابتدا جمعیت خود را بر اساس رنگ های مختلف قرمز، زرد، سبز و آبی به زیر گروه هایی تقسیم کردیم. سپس از هر رنگ، یک فرد را به نسبت تعداد آنها در جمعیت انتخاب کردیم.
سه نوع نمونهبرداری تصادفی طبقهای وجود دارد:
1.3.1- نمونهبرداری تصادفی طبقهای متناسب
در اینجا، ما هر گروه را به نسبت نمایندگی آن در کل جمعیت مورد مطالعه تقسیم میکنیم. برای مثال: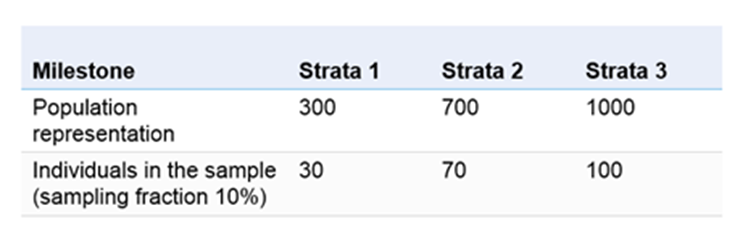
1.3.2- نمونهبرداری تصادفی طبقهای نامتناسب
در نمونهبرداری تصادفی طبقهای نامتناسب، با تقسیمبندی نمونه پیش نمیرویم. هدف در اینجا این است که اطمینان حاصل شود که همه گروههای جامعه بدون در نظر گرفتن نسبت نمایندگی آنها در جامعه، در نمونه نمایندگی پیدا میکنند.
1.3.3- نمونهبرداری طبقه ای بهینه
در نمونهبرداری طبقهای بهینه، گروهها را به نسبت انحراف معیار مشاهدات آنها تشکیل میدهیم. این روش به تخصیص بهینه Neyman نیز معروف است. در این روش، تخصیص بهینه می شود زیرا اندازه طبقه و همچنین تنوع در جمعیت را در نظر میگیرد.
مزایا:
- درصد بیشتری از همه گروه ها نماینده دارند.
- اگر یکنواختی در لایهها و تنوع در بین طبقات وجود داشته باشد، تخمینها می توانند دقیق باشند.
معایب:
- روش شناسی پیچیده
- احتمالاً پرهزینه تر و وقت گیرتر
- نیاز به درک عضویت طبقهها دارد.
مثال ۱: محققی که به دنبال تجزیه و تحلیل ویژگیهای افراد متعلق به بخشهای مختلف درآمد سالانه است، طبق درآمد سالانه خانواده، طبقهها (گروهها) را ایجاد میکند. به عنوان مثال، کمتر از 20000 دلار، 21000 دلار تا 30000 دلار، 31000 دلار تا 40000 دلار، 41000 دلار تا 50000 دلار و غیره. محقق با انجام این کار، ویژگیهای افراد متعلق به گروههای درآمدی مختلف را بررسی میکند. بازاریابان می توانند تجزیه و تحلیل کنند که کدام گروههای درآمدی را هدف قرار دهند و کدام یک را حذف کنند تا نقشهای ایجاد کنند که نتایج دقیقتری داشته باشد.
مثال ۲: یک شرکت 800 کارمند زن و 200 کارمند مرد دارد. شما می خواهید اطمینان حاصل کنید که نمونه منعکس کننده تعادل جنسیتی شرکت است، بنابراین جمعیت را بر اساس جنسیت به دو دسته، طبقهبندی میکنید. سپس برای هر گروه، از نمونهبرداری تصادفی استفاده میکنید و 80 زن و 20 مرد را انتخاب می کنید که نمونه ی نماینده 100 نفر را به شما ارائه میدهد.
1.4- نمونهبرداری خوشهای (Cluster sampling)
نمونهبرداری خوشهای روشی است که در آن محققین کل جمعیت را به بخشها یا خوشههایی که یک جامعه را نشان میدهند تقسیم میکنند. خوشهها بر اساس پارامترهای جمعیت شناختی مانند سن، جنس، مکان و غیره شناسایی و در یک نمونه گنجانده میشوند و به جای نمونهبرداری از افراد از هر زیرگروه، به طور تصادفی زیر گروهها انتخاب میشوند. این روش برای برخورد با جمعیتهای بزرگ و پراکنده خوب است، اما خطر خطا در نمونه بیشتر است، زیرا ممکن است تفاوتهای اساسی بین خوشهها وجود داشته باشد. تضمین اینکه خوشههای نمونهبرداری شده واقعاً نماینده کل جمعیت باشند، دشوار است. 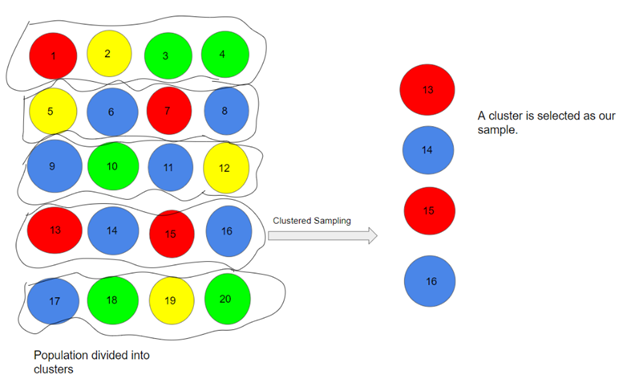
در مثال بالا، ما جمعیت خود را به 5 خوشه تقسیم کرده ایم. هر خوشه شامل 4 فرد است و ما خوشه چهارم را در نمونه خود انتخاب کردهایم. ما میتوانیم خوشههای بیشتری را با توجه به حجم نمونه خود اضافه کنیم.
نمونهبرداری تصادفی طبقهای در مقابل نمونهبرداری خوشهای
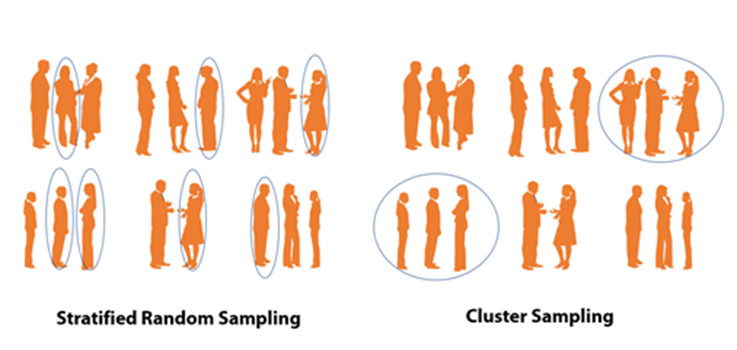
قبل از پرداختن به روش نمونهبرداری احتمالی بعدی، بیایید تفاوت بین نمونهبرداری تصادفی طبقهای و نمونهبرداری خوشهای را بررسی کنیم.
در نمونهبرداری تصادفی طبقهای، ابتدا از ویژگیهای مشترک برای تقسیم کل جامعه به طبقات استفاده میکنیم و سپس عناصری را از هر طبقه انتخاب میکنیم. در خوشهبندی، کل جمعیت را به خوشهها تقسیم میکنیم و سپس بهطور تصادفی خوشههایی را انتخاب میکنیم تا یک نمونه تشکیل شود و نه عناصر درون خوشهها.
مزایا:
- زمان و هزینه را کاهش می دهد.
- کاربردی و آسان برای استفاده.
- می توان از نمونه های بزرگتر استفاده کرد.
معایب:
- افزایش خطا در نمونهبرداری
- تنوع قاب نمونه ممکن است به خوبی منعکس نشود.
مثال ۱: فرض کنید دولت ایالات متحده می خواهد تعداد مهاجرانی که در شهرهای اصلی ایالات متحده زندگی می کنند را ارزیابی کند. در این صورت، آنها می توانند آن را به خوشههایی بر اساس ایالتهایی مانند کالیفرنیا، تگزاس، فلوریدا، ماساچوست، کلرادو، هاوایی و غیره تقسیم کنند. این روش برای انجام نظرسنجی موثرتر خواهد بود زیرا نتایج در ایالتها سازماندهی میشود و دادههای واقعیتری درباره مهاجرت ارائه میدهد.
مثال ۲: یک شرکت دارای دفاتری در 10 شهر در سراسر کشور است (همه با تعداد کارمندان تقریباً یکسان در نقشهای مشابه). شما ظرفیت سفر به هر اداره را برای جمعآوری دادههای خود را ندارید، بنابراین از نمونهبرداری تصادفی برای انتخاب 3 دفتر استفاده میکنید که اینها خوشه های شما هستند.
موارد استفاده از نمونهبرداری احتمالی
استفادههای متعددی از نمونهبرداری احتمالی وجود دارد:
- کاهش سوگیری نمونه: با استفاده از روش نمونهبرداری احتمالی، سوگیری تحقیق در نمونه مشتق شده از یک جامعه ناچیز یا هیچ است. انتخاب نمونه عمدتاً درک و استنباط محقق را به تصویر میکشد. نمونهبرداری احتمالی منجر به جمعآوری دادههای با کیفیت بالاتر میشود، زیرا نمونه بهطور مناسب جامعه را نشان میدهد.
- جمعیت متنوع: زمانی که جمعیت گسترده و متنوع است، داشتن نماینده کافی ضروری است تا دادهها به سمت یک جمعیت خاص منحرف نشوند.
- ایجاد یک نمونه دقیق: نمونهبرداری احتمالی به محققین کمک می کند تا یک نمونه دقیق را برنامه ریزی و ایجاد کنند که این به دستیابی به دادههای کاملاً تعریف شده کمک می کند.
2. انواع نمونهبرداری غیر احتمالی با مثال
روشهای نمونهبرداری غیر احتمالی، برای نتیجه گرفتن رفتار یک جامعه بر اساس نمونه آن استفاده نمیشوند، بلکه از آنها زمانی استفاده میشود که تمرکز تحقیق بر روی درک پیچیدگی یک قضیه یا اتفاق است. در این روش، افراد بر اساس معیارهای غیرتصادفی انتخاب میشوند یعنی همه اعضا شانس انتخاب شدن ندارند و شانس هر عضو هم مشخص نیست. پس میزان تعمیمپذیری به کل جامعه و میزان خطا نیز مشخص نیست. محاسبه نمونه در این روش، آسانتر و ارزانتر است، اما خطر سوگیری نمونه بالاتری وجود دارد. این بدان معناست که استنباطهایی که میتوانید در مورد جامعه انجام دهید نسبت به نمونههای احتمالی ضعیفتر است و نتیجهگیریهای شما ممکن است محدودتر باشند. اگر از نمونه غیراحتمالی استفاده میکنید، همچنان باید هدف خود را بسازید به طوری که تا حد ممکن معرف جامعه باشد. روش های نمونهبرداری غیر احتمالی اغلب در تحقیقات اکتشافی و کیفی استفاده میشوند. در این نوع تحقیقات، هدف آزمایش یک فرض در مورد یک جمعیت گسترده نیست، بلکه ایجاد درک اولیه ازانواع نمونهبرداری غیر احتمالی یک جمعیت کوچک مورد تحقیق است.
چهار نوع نمونهبرداری غیراحتمالی زیر، هدف این روش نمونهبرداری را به نحو بهتری توضیح میدهند: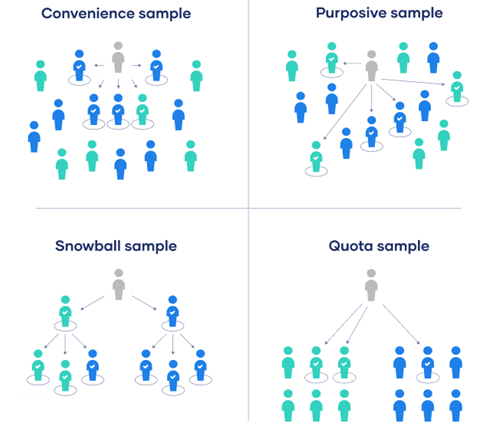
2.1- نمونهبرداری آسان (Convenience sampling)
نمونهبرداری آسان، به سادگی شامل افرادی میشود که به طور اتفاقی برای محقق بیشترین دسترسی را دارند، مانند نظرسنجی از مشتریان در یک مرکز خرید یا عابران در یک خیابان شلوغ. معمولاً به دلیل سهولت محقق در انجام آن و برقراری ارتباط با اعضای نمونه، آن را نمونهبرداری آسان مینامند. محققان تقریباً هیچ اختیاری برای انتخاب عناصر نمونه ندارند و این کار صرفاً بر اساس نزدیکی انجام میشود و نه نماینده بودن. این روش نمونهبرداری غیر احتمالی، زمانی استفاده می شود که محدودیت زمانی و هزینهای در جمع آوری دادهّّها وجود داشته باشد. اگر چه این یک روش، یک راه آسان و ارزان برای جمعآوری دادههای اولیه است، اما راهی برای تشخیص اینکه آیا نمونه نماینده جامعه است وجود ندارد، بنابراین نمیتواند نتایج قابلتعمیم تولید کند. نمونههای راحت هم در معرض خطر سوگیری نمونهبرداری و هم سوگیری انتخاب هستند.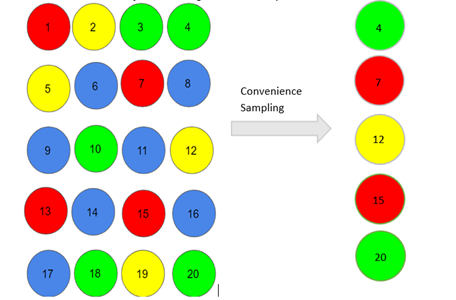
در اینجا، افراد با شماره های 4، 7، 12، 15 و 20 بخشی از نمونه هستند.
مزایا:
- به دست آوردن نمونه نسبتاً آسان است.
- مقرون به صرفه
- شرکت کنندگان به راحتی در دسترس هستند.
معایب:
- نتایج را نمی توان تعمیم داد.
- احتمال عدم تعادل در نماینده بودن جمعیت
- افزایش تعصب در چارچوب نمونه
مثال ۱: استارتآپها و سازمانهای غیردولتی معمولاً برای توزیع بروشورهای رویدادهای آینده یا تبلیغ یک هدف، نمونهبرداری آسان را در یک مرکز خرید انجام میدهند.آنها این کار را با ایستادن در ورودی مرکز خرید و دادن بروشورها به صورت تصادفی انجام میدهند.
مثال ۲: شما در حال تحقیق درباره نظرات در مورد خدمات پشتیبانی دانشجویی در دانشگاه خود هستید، بنابراین پس از هر کلاس، از دانشجویان کلاس خود می خواهید که یک نظرسنجی در مورد موضوع انجام دهند. این یک روش آسان و دردسترس برای جمعآوری دادهها است. اما از آنجایی که شما فقط از دانشجویانی که کلاسهای مشابهی را با شما در همان سطح میگذرانند، نظرسنجی کردهاید، نمونه نماینده همه دانشجویان دانشگاه شما نیست.
2.2- نمونهبرداری قضاوتی یا هدفمند (Judgmental or purposive sampling)
نمونههای قضاوتی یا هدفمند به صلاحدید محقق تشکیل میشوند. محققان صرفاً هدف مطالعه را همراه با درک مخاطب هدف در نظر می گیرند. 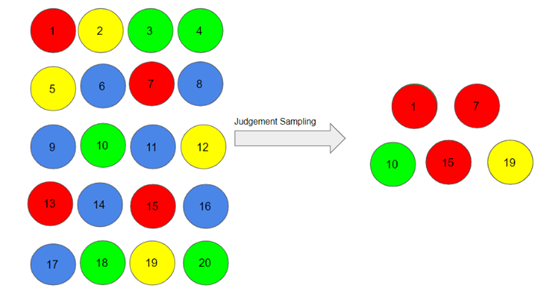
فرض کنید کارشناسان معتقدند که افراد 1، 7، 10، 15 و 19 باید برای نمونه در نظر گرفته شوند زیرا ممکن است به ما در استنباط بهتر جامعه کمک کنند. همانطور که می توانید تصور کنید، نمونهبرداری سهمیه ای نیز مستعد سوگیری از سوی کارشناسان است و ممکن است لزوما نماینده جامعه نباشد.
مزایا:
- نسبتاً ارزان و زمان کمتر
- محققان را قادر می سازد تا مستقیماً با بازار هدف خود تماس بگیرند.
- نتایج تقریباً به صورت real-time آماده میشوند
معایب:
- خطر اشتباه محقق در قضاوت
- سطح تعصب زیاد است و قابلیت اطمینان پایین است.
- مشکل در تعمیم نتایج مطالعه
مثال ۱: زمانی که محققان می خواهند روند فکری افراد علاقهمند به تحصیل در مقطع کارشناسی ارشد خود را بررسی کنند، معیارهای انتخاب این خواهد بود: "آیا شما علاقهمند هستید کارشناسی ارشد خود را در ... انجام دهید؟" و کسانی که با "نه" پاسخ میدهند از نمونه حذف میشوند.
مثال ۲: شما می خواهید در مورد نظرات و تجربیات دانشجویان معلول در دانشگاه خود بیشتر بدانید، بنابراین به طور هدفمند تعدادی از دانشجویان با نیازهای پشتیبانی متفاوت را انتخاب می کنید تا طیف متنوعی از دادهها را در مورد تجربیات آنها با خدمات دانشجویی جمع آوری کنید.
2.3- نمونهبرداری گلوله برفی (Snowball sampling)
نمونهبرداری گلوله برفی روشی نمونهبرداری است که محققان در مواقعی که ردیابی افراد مشکل باشد از آن استفاده می کنند. برای مثال، بررسی افراد بی پناه یا مهاجران غیرقانونی بسیار چالش برانگیز خواهد بود. در چنین مواردی، پژوهشگر ابتدا افرادی را شناسایی میکند و پس از دریافت اطلاعات از آنها میخواهد که فرد یا افراد دیگری را به وی معرفی کنند. محققان همچنین این روش نمونهبرداری را زمانی اجرا میکنند که موضوع بسیار حساس است و آشکارا مورد بحث قرار نمیگیرد. نقطه ضعف این روش، نماینده نبودن است، زیرا به دلیل اتکا به شرکت کنندگان خاص، راهی برای دانستن اینکه نمونه شما چقدر نمایندهی جامعه است، وجود ندارد. این روش نیز می تواند منجر به سوگیری نمونهبرداری شود.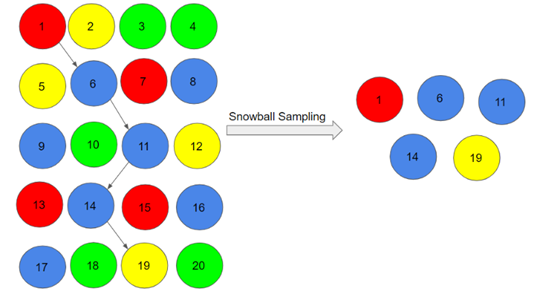
در اینجا به طور تصادفی فرد 1 را برای نمونه انتخاب کردیم و سپس او فرد 6 و فرد 6 فرد 11 و ... را توصیه کرد. 1-6-11-14-19
در نمونه برداری گلوله برفی خطر سوگیری انتخابی قابل توجهی وجود دارد، زیرا افراد ارجاع شده ویژگیهای مشترکی را با فردی که آنها را توصیه می کند به اشتراک می گذارند.
در نمونهبرداری گلوله برفی سه زیرمجموعه وجود دارد: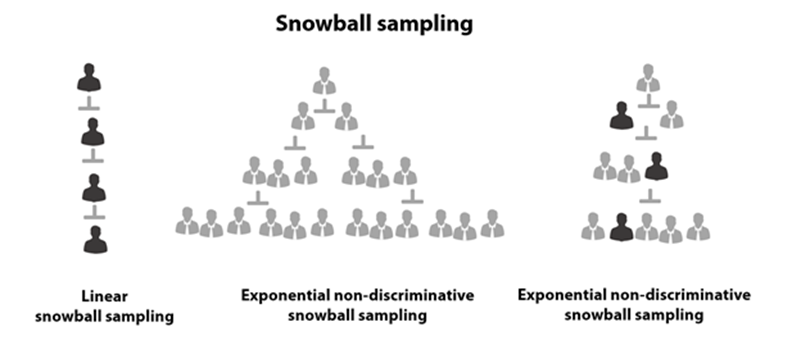
2.3.1- نمونهبرداری گلوله برفی خطی
زنجیره به صورت خطی رشد می کند. هر عضو در نمونه به یک عضو دیگر اشاره دارد.
2.3.2- نمونهبرداری گلوله برفی بدون تمایز نمایی
روابط یک به چند. هر عضو در مطالعه به چند عضو اشاره دارد و همه در مطالعه انتخاب میشوند، که این یک اثر نمایی بر اندازه نمونه ایجاد می کند. همانطور که ممکن است حدس بزنید، این ممکن است سوگیری را در نمونهبرداری ایجاد کند و محققان هیچ ایده ای ندارند که آیا نمونه نماینده جامعه مورد مطالعه است یا خیر.
2.3.3- نمونهبرداری گلوله برفی تمایزی نمایی
در اینجا، در حالی که از عضو درخواست میکنیم که چندین ارجاع ارائه کند، تنها یکی از این موارد را انتخاب میکنیم و بقیه ارجاعها را باطل میکنیم. با انجام این کار، محققان تلاش میکنند تا شانس سوگیری در روش نمونهبرداری را کاهش دهند.
مزایا:
- محققان می توانند به موضوعات غیر معمول در یک جامعه خاص دسترسی داشته باشند.
- ارزان و ساده برای اجرا.
- موضوعات مختلف را می توان بدون کمک کارمندان انجام داد.
معایب:
- این امکان وجود دارد که نمونه نماینده نباشد.
- سوگیری در نمونهبرداری ممکن است وجود داشته باشد.
- نتیجه گیری قطعی در مورد جمعیت گسترده تر ممکن است چالش برانگیز باشد زیرا نمونه در معرض سوگیری است.
مثال ۱: نظرسنجی برای جمعآوری اطلاعات درباره ایدز .(HIV) قربانیان ایدز به راحتی به سوالات پاسخ نمیدهند. با این حال، محققان می توانند با افرادی که ممکن است بشناسند یا داوطلبانی که با علت مرتبط هستند تماس بگیرند به جای اینکه با قربانیان تماس بگیرند و اطلاعات را جمع آوری کنند.
مثال ۲: شما در حال تحقیق در مورد تجربیات بی خانمانی در شهر خود هستید. از آنجایی که لیستی از همه افراد بی خانمان در شهر وجود ندارد، نمونهبرداری احتمالی امکان پذیر نیست. شما با یک نفر آشنا می شوید که موافقت می کند در تحقیق شرکت کند و او شما را با افراد بی خانمان دیگری که در منطقه می شناسد، در تماس قرار می دهد.
2.4- نمونهبرداری سهمیهای (Quota sampling)
نمونهبرداری سهمیهای بر انتخاب غیر تصادفی یک تعداد از پیش تعیین شده واحدها یا نسبتها (یعنی سهمیه) متکی است. در این روش، ابتدا جمعیت را به زیرگروههایی تقسیم میکنید (که طبقات نامیده میشوند) و سپس واحدهای نمونه را تا رسیدن به سهمیه خود انتخاب میکنید. این واحدها، ویژگی های خاصی دارند که توسط شما قبل از تشکیل طبقهها تعیین شده است. هدف از نمونهبرداری سهمیهای، کنترل این موضوع است که چه چیزی یا چه کسی نمونه شما را تشکیل میدهد. در نمونهبرداری سهمیهای دو زیرمجموعه وجود دارد:
- نمونهبرداری سهمیهای کنترلشده: در این روش با اعمال محدودیتهای خاص، نمونههایی که محققان میتوانند انتخاب کنند، محدود میشوند.
- نمونهبرداری سهمیه ای کنترل نشده: در نمونهبرداری سهمیه ای کنترل نشده، محقق مجاز است افراد گروه نمونه را انتخاب کند.
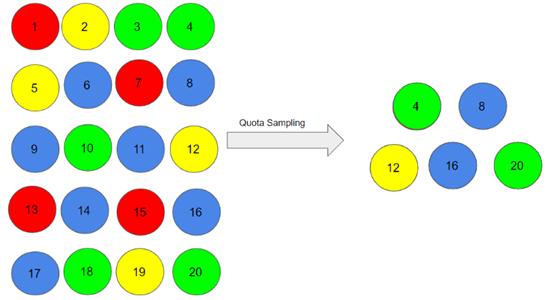
بنابراین، افراد با شماره های 4، 8، 12، 16 و 20 برای نمونه انتخاب شدهاند.
در نمونهبرداری سهمیه ای، نمونه انتخابی ممکن است بهترین نمایش دهنده ویژگی های جمعیتی نباشد که در نظر گرفته نشده اند.
مزایا:
- مقرون به صرفه
- مستقل از چارچوب نمونه
- این فرصت را برای پژوهشگران فراهم می کند تا یک زیر گروه خاص را مطالعه کنند.
معایب:
- احتمال ایجاد نمونه بزرگ
- محاسبه خطای نمونهبرداری غیرممکن است.
- بی کفایتی و/یا بیتجربگی محققان ممکن است منجر به سوگیری و کار غیر استاندارد شود.
مثال: شما میخواهید نظر مصرفکننده را به خدمات تحویل محصول جدید در بوستون، با تمرکز بر ترجیحات غذایی، بسنجید. شما جمعیت را به گوشت خواران، گیاهخواران و وگان ها تقسیم می کنید و نمونه ای 1000 نفری را می گیرید. از آنجایی که این شرکت میخواهد به همه مصرفکنندگان پاسخ دهد، شما برای هر گروه رژیمی 200 نفر سهمیه تعیین میکنید. به این ترتیب، همه ترجیحات غذایی به طور مساوی در تحقیقات شما قرار میگیرند و شما به راحتی می توانید این گروه ها را با هم مقایسه کنید. شما تا زمانی که به سهمیه 200 شرکت کننده برای هر زیرگروه برسید، به انتخاب ادامه میدهید.
موارد استفاده از نمونهبرداری غیراحتمالی
نمونهبرداری غیراحتمالی برای موارد زیر استفاده میشود:
- ایجاد فرض: محققان از روش نمونهبرداری غیراحتمالی برای ایجاد فرض، زمانی که محدود هستند و اطلاعات قبلی در دسترس نیست، استفاده می کنند. این روش با سرعت بیشتری دادهها را آماده میکند و پایه ای برای تحقیقات بیشتر ایجاد می کند.
- تحقیق اکتشافی: محققان از این روش نمونهبرداری به طور گسترده در هنگام انجام تحقیقات کیفی، مطالعات آزمایشی یا تحقیقات اکتشافی استفاده میکنند.
- محدودیتهای بودجه و زمان: روش غیر احتمالی، زمانی که محدودیتهای بودجه و زمانی وجود دارد و باید برخی دادههای اولیه جمعآوری شود، مورد استفاده قرار میگیرد.
چگونه در مورد نوع نمونهبرداری تصمیم گرفته شود؟
برای هر تحقیقی، انتخاب دقیق روش نمونهبرداری برای دستیابی به اهداف مطالعه ضروری است. اثربخشی نمونهبرداری به عوامل مختلفی بستگی دارد. در اینجا مراحلی که محققان خبره برای تصمیم گیری بهترین روش نمونهبرداری، دنبال می کنند، آورده شده است:
- اهداف تحقیق را یادداشت کنید که به طور کلی، باید ترکیبی از هزینه یا دقت باشد.
- تکنیک های نمونهبرداری موثری را که ممکن است به طور بالقوه به اهداف تحقیق دست یابند، شناسایی کنید.
- هر یک از این روشها را آزمایش کنید و بررسی کنید که آیا آنها به هدف شما کمک می کنند یا خیر.
- روشی را انتخاب کنید که بهترین کار را برای تحقیق دارد.
تفاوت بین روشهای نمونهبرداری احتمالی و نمونهبرداری غیراحتمالی
تا اینجا، انواع مختلف روشهای نمونهبرداری و انواع فرعی آنها را بررسی شدند. اکنون، برای خلاصه کردن کل بحث، بیایید نگاهی کلی به تفاوتهای مهم بین روشهای نمونهبرداری احتمالی و روشهای نمونهبرداری غیراحتمالی داشته باشیم.
| روشهای نمونهبرداری احتمالی | روشهای نمونهبرداری غیراحتمالی |
تعریف | نمونهبرداری احتمالی یک روش نمونهبرداری است که در آن نمونه هایی از جمعیت بزرگتر با استفاده از روشی بر اساس تئوری احتمال انتخاب می شوند. | نمونهبرداری غیراحتمالی روش نمونهبرداری است که در آن، محقق نمونهها را بر اساس قضاوت ذهنی به جای انتخاب تصادفی، انتخاب می کند.
|
عنوان جایگزین | روش نمونهبرداری تصادفی. | روش نمونهبرداری غیرتصادفی.
|
انتخاب جمعیت | جامعه به صورت تصادفی انتخاب میشود. | جمعیت به صورت دلخواه انتخاب میشود.
|
ماهیت | تحقیق قطعی است. | تحقیق اکتشافی است.
|
نمونه | از آنجایی که روشی برای تعیین نمونه وجود دارد، ساختار جمعیت به طور قطعی نشان داده میشود. | از آنجایی که روش نمونهبرداری دلخواه است، ساختار جمعیت تقریباً همیشه skewed است.
|
مدت زمان لازم | مدت انجام آن، بیشتر طول میکشد زیرا طراحی تحقیق، نیاز به تعریف پارامترهای انتخاب، قبل از شروع مطالعه و تحقیقات دارد. | این نوع روش نمونهبرداری، سریع است زیرا نه نمونه و نه معیار انتخاب نمونه نیاز به تعریف ندارد.
|
نتایج | این نوع نمونهبرداری، کاملاً بی طرفانه است. از این رو، نتایج نیز قطعی است. | این نوع نمونهبرداری، کاملاً سوگیری دارد و از این رو نتایج نیز سوگیری دارند و تحقیق به صورت حدس و گمان، بیان میشود. |
فرض | در نمونهبرداری احتمالی، قبل از شروع مطالعه، یک فرضیه زیربنایی وجود دارد و هدف این روش اثبات فرض است. | در نمونهبرداری غیراحتمالی، پس از انجام پژوهش، فرض به دست می آید.
|
نتیجه گیری
در این مقاله، فرآیند نمونهبرداری، تکنیک ها و موارد استفاده از آن را پوشش دادیم. در علم داده و یادگیری ماشین، درک فرایند نمونهبرداری به شما کمک میکند تا انتخاب دقیق مدل، پردازش دادهها و انجام تجزیه و تحلیلهای پیشبینیکننده را بهطور مؤثر انجام دهید. همچنین به شما این امکان را می دهد که هر گونه انحراف از مدلی که بر اساس دادههای نمونه میسازید را توضیح دهید، به طوری که به تحقیق و بررسی کل جمعیت برای جمعآوری بینشهای عملی نیاز نباشد.